
In many situations, there is a symmetric matrix of interest  , but one only has a perturbed version of it
, but one only has a perturbed version of it  . How is
. How is  affected by
affected by  ?
?
The basic example is Principal Component Analysis (PCA). Let  for some random vector
for some random vector  , and let
, and let  be the sample covariance matrix on independent copies of
be the sample covariance matrix on independent copies of  . Namely, we observe
. Namely, we observe  i.i.d. random variable distributed as and we set
i.i.d. random variable distributed as and we set
![\[\hat{\Sigma} := \frac{1}{n} \sum_{i=1}^{n} X_i X_i^{\top}.\]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-a76521f859a76faba4c66a9de28dd092_l3.png "Rendered by QuickLaTeX.com")
is concentrated on a low dimensional subspace, then we can hope to discover this subspace from the principal components of . How accurate is the subspace we find?
1. Some intuition
An eigenspace of  is the span of some eigenvectors of . We can decompose into its action on an eigenspace
is the span of some eigenvectors of . We can decompose into its action on an eigenspace  and its action on the orthogonal complement
and its action on the orthogonal complement  :
:
![\[\Sigma = E_0\Lambda_0E_0^* + E_1\Lambda_1E_1,\]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-8467b999772c7e1398d84cbf6aee2c2b_l3.png "Rendered by QuickLaTeX.com")
where
 is an orthonormal basis for (e.g., the eigenvectors of that span ), and
is an orthonormal basis for (e.g., the eigenvectors of that span ), and  is an orthonormal basis for (this follows from the spectral theorem). We can similarly decompose
is an orthonormal basis for (this follows from the spectral theorem). We can similarly decompose with respect to a “corresponding” eigenspace
with respect to a “corresponding” eigenspace  (with dim
(with dim dim
dim ):
): ![\[\hat{\Sigma} = F_0\widehat{\Lambda}_0 F_0^*+ F_1 \widehat{\Lambda}_1 F_1^*.\]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-fadc7436705de408583f00f22a9569e0_l3.png "Rendered by QuickLaTeX.com")
Suppose we find a few eigenvalues of
that somehow stand out from the rest. For instance, as in PCA, we may find the first few eigenvalues to be much larger than the rest. Let  be the corresponding eigenspace. If there is a similarly outstanding group of eigenvalues of , then the hope is that the corresponding eigenspace will be close to in some sense. For instance, we may be interested in how well approximates vectors in . Any vector in can be written as
be the corresponding eigenspace. If there is a similarly outstanding group of eigenvalues of , then the hope is that the corresponding eigenspace will be close to in some sense. For instance, we may be interested in how well approximates vectors in . Any vector in can be written as  for some
for some  , the projection of this vector onto is
, the projection of this vector onto is  . Then
. Then 
Therefore vectors in will be well-approximated by if  is “small”.
is “small”.
The condition we will need is separation between the eigenvalues corresponding to and those corresponding to  . Suppose the eigenvalues corresponding to are all contained in an interval
. Suppose the eigenvalues corresponding to are all contained in an interval ![[a, b]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-b28ebca9266518f1a778b4a4b102a2e1_l3.png "Rendered by QuickLaTeX.com") . Then we will require that the eigenvalues corresponding to be excluded from the interval
. Then we will require that the eigenvalues corresponding to be excluded from the interval  for some
for some  . To see why this is necessary, consider the following example:
. To see why this is necessary, consider the following example:
![\[\Sigma := \begin{bmatrix} 1+\delta & 0 \\ 0 & 1-\delta \end{bmatrix}, \quad H:=\begin{bmatrix} -\delta & \delta \\ \delta & -\delta \end{bmatrix}, \quad \hat{\Sigma} := \begin{bmatrix} 1 & \delta \\ \delta & 1 \end{bmatrix}.\]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-3e12041ba6da5274ec87414ae79582a5_l3.png "Rendered by QuickLaTeX.com")
Here, the “size” of
is comparable to the gap between the relevant eigenvalues. Then the eigenvalues of are  and
and  , and its corresponding eigenvectors are
, and its corresponding eigenvectors are  and
and  . The eigenvalues of are also
. The eigenvalues of are also  and
and  , but its corresponding eigenvectors are
, but its corresponding eigenvectors are  and
and  , we have
, we have  , which can be
, which can bearbitrarily large relative to
 .
.
2. Distances between subspaces
Let  and
and  be
be  -dimensional subspaces of
-dimensional subspaces of  , with
, with  . Let
. Let  and
and  be projectors onto these two subspaces.
be projectors onto these two subspaces.
We first consider the angle between two vectors, that is, when  . Then, and are spanned by vectors. Denote the two corresponding vectors as
. Then, and are spanned by vectors. Denote the two corresponding vectors as  . The angle between
. The angle between  and
and  is defined as:
is defined as:
![\[(v_1, v_2) = \cos^{-1}\left( v_1^* v_2\right).\]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-81833f087d00b04e16ba019a3f9dc896_l3.png "Rendered by QuickLaTeX.com")
Now, we need to extend this concept to subspaces (when
 ). Let
). Let  and
and  be
be  matrices with orthonormal columns such that range()
matrices with orthonormal columns such that range()  and range()
and range()  . Then, the projectors can be written as
. Then, the projectors can be written as  and
and  .
.Now, we define the angle between subspaces
and as the following:Definition
The canonical or principal angles between and are:
![\[\theta_1 = \cos^{-1}(\sigma_1),\dots , \theta_r = \cos^{-1}( \sigma_r),\]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-7db25526c3a7671421dcaccf3e0798a2_l3.png "Rendered by QuickLaTeX.com")
where
 are singular values of
are singular values of  or
or  .
.
A general result known as CS-decomposition in linear algebra gives the following:
![\[E^*F = U \cos \Theta V^*,\]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-a5d9fe44b043efd3929b0dc1d43272c7_l3.png "Rendered by QuickLaTeX.com")
where
![\[\Theta = \begin{bmatrix} \theta_1 & \dots & 0 \\ \vdots & \dots & \vdots \\ 0 & \dots & \theta_r \end{bmatrix}\]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-f9385e6988084442cc05f07f7052e2e3_l3.png "Rendered by QuickLaTeX.com")
Another way of defining canonical angles is the following:
Definition
The canonical angles between the spaces and are  for
for  , where
, where  are the singular values of
are the singular values of
![\[\Pi_{\mathcal E} \left( I - \Pi_{\mathcal F}\right)=E E^*\left( I- F F^* \right) = U \sin \Theta V^*.\]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-cc9d7d7a2ffcb46c9dd33180c93ea6df_l3.png "Rendered by QuickLaTeX.com")
Now, given the definition of the canonical angles, we can define the distances between subspaces and as the following.
Definition
The distance between and is  , which is a metric over the space of -dimensional linear subspaces of . Equivalently,
, which is a metric over the space of -dimensional linear subspaces of . Equivalently,

3. Davis Kahan Theorem
Theorem
Let  and
and  be symmetric matrices with
be symmetric matrices with ![[E_0, E_1]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-6f9fb854b6dcdf52bb1ab69d8b7ca88b_l3.png "Rendered by QuickLaTeX.com") and
and ![[F_0, F_1]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-b6c76ee07a69530ef6495d6ab0398b80_l3.png "Rendered by QuickLaTeX.com") orthogonal matrices. If the eigenvalues
orthogonal matrices. If the eigenvalues  are contained in an interval
are contained in an interval  , and the eigenvalues of
, and the eigenvalues of  are excluded from the interval
are excluded from the interval  for some , then
for some , then
![\[\|F_1^*E_0\| \leq \frac{\|F_1^*HE_0\|}{\delta} ,\]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-86ec1c116b826f35b380043b3584a9a2_l3.png "Rendered by QuickLaTeX.com")
for any unitarily invariant norm
 .
.
Proof.
Since  we have
we have

Furthermore,
 , so
, so 
Let
 and
and  . By the triangle inequality, we have
. By the triangle inequality, we have 
Here we have used a centering trick so that
 has eigenvalues contained in
has eigenvalues contained in ![[-r, r]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-a84a1f09e39415d77a0fb8f09d8dda3f_l3.png "Rendered by QuickLaTeX.com") , and
, and has eigenvalues excluded from
has eigenvalues excluded from  . This implies that
. This implies that  and
and  , respectively. Therefore
, respectively. Therefore 
and

We conclude that

Another version of the Davis-Kahan Theorem which is more popular in the community of statisticians is the following.
Theorem
Let and be  symmetric matrices with respective eigenvalues
symmetric matrices with respective eigenvalues  and
and  .
.
Fix  , and let
, and let  and
and  be
be  matrices with orthonormal columns corresponding to eigenvalues
matrices with orthonormal columns corresponding to eigenvalues  and
and  .
.
Let and be the subspaces spanned by columns of and . Define the eigengap as
![\[\delta = \inf \left\{ \left| \lambda - \hat{\lambda} \right| \; : \; \lambda \in [\lambda_s , \lambda_r], \; \hat{\lambda} \in (- \infty, \hat{\lambda}_{s+1}] \cup [\hat{\lambda}_{r-1}, \infty)\right\},\]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-7a02ad4b4d88b6da780737eb16779934_l3.png "Rendered by QuickLaTeX.com")
where we define
 and
and  .
.If
, then ![\[\left\|\mathrm{sin} \Theta(\mathcal E, \mathcal F)\right\|_2 \leq \frac{\|\hat{\Sigma}-\Sigma\|_{2}}{\delta}.\]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-7676988cbcfce89a5ebab100bfc76d70_l3.png "Rendered by QuickLaTeX.com")
The result also holds for the operator norm
 .
.
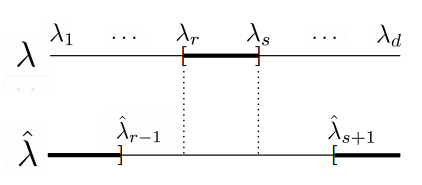 . (Source: Alessandro Rinaldo Lecture Notes)
. (Source: Alessandro Rinaldo Lecture Notes)By Weyl’s theorem, one can show that the sufficient (but not necessary) condition for  in Davis-Kahan theorem is
in Davis-Kahan theorem is
![\[\|\hat{\Sigma}-\Sigma\|_2<\min_{r\leq i\leq s, \; j \in [n] \backslash \{r,\dots,s\}} \left| \lambda_i-\hat{\lambda}_j\right|.\]](https://quentin-duchemin.alwaysdata.net/wiki/wp-content/ql-cache/quicklatex.com-d927454d972d3f9afea5a70e399e7680_l3.png "Rendered by QuickLaTeX.com")
When the matrices are not symmetric, there exists a generalized version of the Davis-Kahan Theorem called Wedin’s theorem.